1. 基础概念
1.1. 缓冲区操作
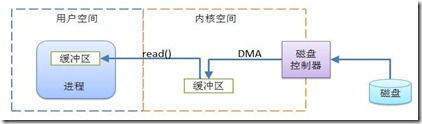
缓冲区及操作是所有I/O的基础,进程执行I/O操作,归结起来就是向操作系统发出请求,让它要么把缓冲区里的数据排干(写),要么把缓冲区填满(读)。如下图
1.2. 内核空间、用户空间
上图简单描述了数据从磁盘到用户进程的内存区域移动的过程,其间涉及到了内核空间与用户空间。这两个空间有什么区别呢?
用户空间就是常规进程(如JVM)所在区域,用户空间是非特权区域,如不能直接访问硬件设备。内核空间是操作系统所在区域,那肯定是有特权啦,如能与设备控制器通讯,控制用户区域的进程运行状态。进程执行I/O操作时,它执行一个系统调用把控制权交由内核。
1.3. I/O模型
常见的I/O模型有以下几种
1.3.1. 同步阻塞I/O
最常用的一个模型是同步阻塞I/O模型。在这个模型中,用户空间的应用程序执行一个系统调用,这会导致应用程序阻塞。这意味着应用程序会一直阻塞,直到系统调用完成为止(数据传输完成或发生错误)。调用应用程序处于一种不再消费 CPU 而只是简单等待响应的状态,因此从处理的角度来看,这是非常有效的。
下图给出了传统的阻塞I/O模型,这也是目前应用程序中最为常用的一种模型。其行为非常容易理解,其用法对于典型的应用程序来说都非常有效。在调用 read 系统调用时,应用程序会阻塞并对内核进行上下文切换。然后会触发读操作,当响应返回时(从我们正在从中读取的设备中返回),数据就被移动到用户空间的缓冲区中。然后应用程序就会解除阻塞(read 调用返回)。
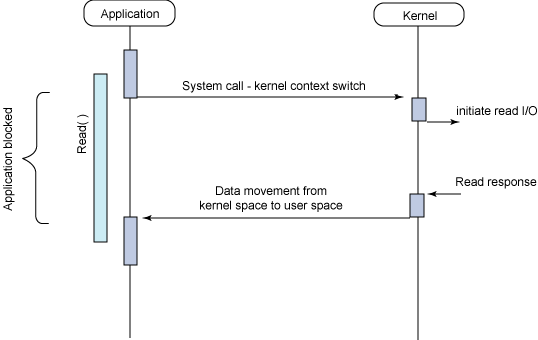
从应用程序的角度来说,read 调用会延续很长时间。实际上,在内核执行读操作和其他工作时,应用程序的确会被阻塞。
1.3.2. 同步非阻塞I/O
同步阻塞I/O的一种效率稍低的变种是同步非阻塞I/O。在这种模型中,设备是以非阻塞的形式打开的。这意味着I/O操作不会立即完成,read 操作可能会返回一个错误代码,说明这个命令不能立即满足(EAGAIN 或 EWOULDBLOCK),如下图所示。
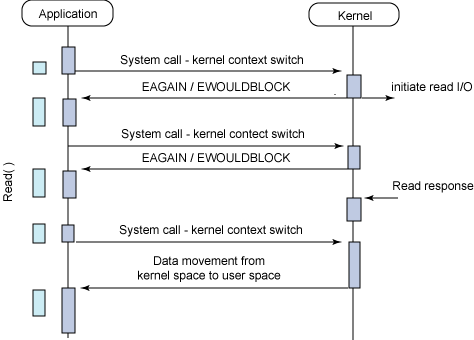
非阻塞的实现是I/O命令可能并不会立即满足,需要应用程序调用许多次来等待操作完成。这可能效率不高,因为在很多情况下,当内核执行这个命令时,应用程序必须要进行忙碌等待,直到数据可用为止,或者试图执行其他工作。正如图 3 所示的一样,这个方法可以引入I/O操作的延时,因为数据在内核中变为可用到用户调用 read 返回数据之间存在一定的间隔,这会导致整体数据吞吐量的降低。
1.3.3. 异步阻塞I/O
另外一个阻塞解决方案是带有阻塞通知的非阻塞I/O。在这种模型中,配置的是非阻塞I/O,然后使用阻塞 select 系统调用来确定一个I/O描述符何时有操作。使 select 调用非常有趣的是它可以用来为多个描述符提供通知,而不仅仅为一个描述符提供通知。对于每个提示符来说,我们可以请求这个描述符可以写数据、有读数据可用以及是否发生错误的通知。
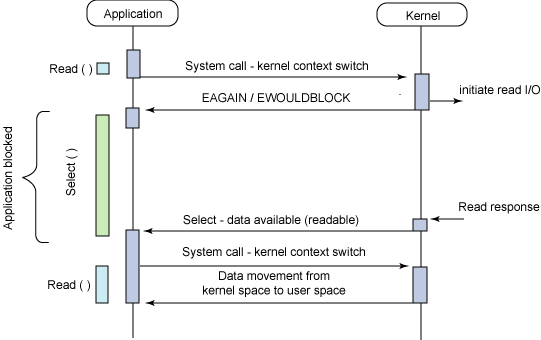
select 调用的主要问题是它的效率不是非常高。尽管这是异步通知使用的一种方便模型,但是对于高性能的I/O操作来说不建议使用。
1.3.4. 异步非阻塞I/O
最后,异步非阻塞I/O模型是一种处理与I/O重叠进行的模型。读请求会立即返回,说明 read 请求已经成功发起了。在后台完成读操作时,应用程序然后会执行其他处理操作。当 read 的响应到达时,就会产生一个信号或执行一个基于线程的回调函数来完成这次I/O处理过程。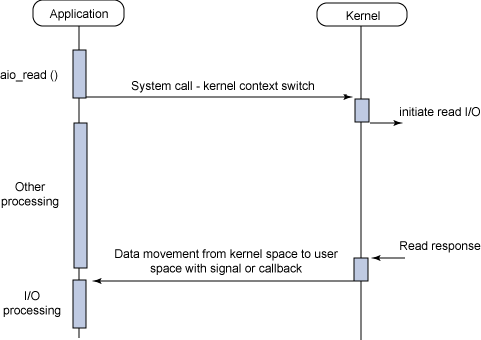
在一个进程中为了执行多个I/O请求而对计算操作和I/O处理进行重叠处理的能力利用了处理速度与I/O速度之间的差异。当一个或多个I/O请求挂起时,CPU 可以执行其他任务;或者更为常见的是,在发起其他I/O的同时对已经完成的I/O进行操作。
2. NIO
开始讲NIO之前,了解为什么会有NIO,相比传统流I/O的优势在哪,它可以用来做什么等等的问题,还是很有必要的。
传统流I/O是基于字节的,所有I/O都被视为单个字节的移动;而NIO是基于块的,大家可能猜到了,NIO的性能肯定优于流I/O。没错!其性能的提高 要得益于其使用的结构更接近操作系统执行I/O的方式:通道和缓冲器。
我们可以把它想象成一个煤矿,通道是一个包含煤层(数据)的矿藏,而缓冲器则是派送 到矿藏的卡车。卡车载满煤炭而归,我们再从卡车上获得煤炭。也就是说,我们并没有直接和通道交互;我们只是和缓冲器交互,并把缓冲器派送到通道。通道要么 从缓冲器获得数据,要么向缓冲器发送数据。(这段比喻出自Java编程思想)。
NIO的主要应用在高性能、高容量服务端应用程序,典型的Netty就是基于它的。
NIO也叫作 None Blocking IO 或者 New IO,在Java1.4纳入JDK中,具有以下特征:
- 为所有的原始类型提供(buffer)缓存支持;
- 使用Charset作为字符集编码解码解决方案;
- 增加了通道(Channel)对象,作为新的原始I/O抽象;
- 支持锁和内存访问文件的文件访问接口;
- 提供了基于Selector的异步网络I/O;
NIO是基于块(Block)的,它以块为基本单位处理数据。在NIO中,最重要的两个组件是buffer缓冲和channel通道。缓冲是一块连续的内存区域,是NIO读写数据的中转站。通道表示缓冲数据的源头或目的地,它用于向缓冲读取或写入数据,是访问缓冲的接口。通道和缓冲的关系如图: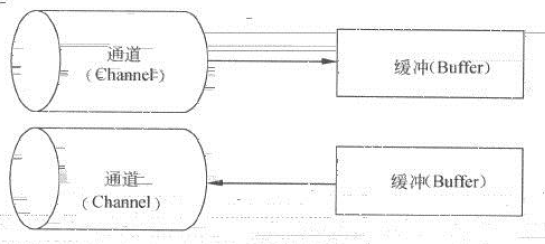
2.1. 缓冲区Buffer概述
缓冲区实质上就是一个数组,但它不仅仅是一个数组,缓冲区还提供了对数据的结构化访问,而且还可以跟踪系统的读/写进程。为什么这么说呢?下面来看看缓冲区的细节。
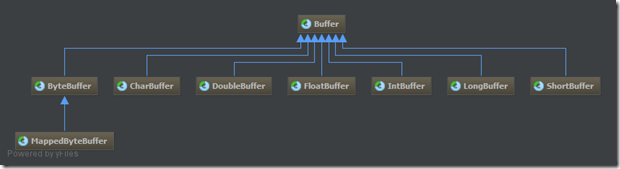
讲缓冲区细节之前,我们先来看一下缓冲区“家谱”:
2.1.1. Buffer属性
Buffer对象有四个基本属性:
- 容量Capacity:缓冲区能容纳的数据元素的最大数量,在缓冲区创建时设定,无法更改
- 上界Limit:缓冲区的第一个不能被读或写的元素的索引
- 位置Position:下一个要被读或写的元素的索引
- 标记Mark:备忘位置,调用mark()来设定mark=position,调用reset()设定position=mark
这四个属性总是遵循这样的关系:0<=mark<=position<=limit<=capacity。
2.2. Buffer类和Channel
JDK为每一种java原生类型都提供了一种Buffer,除了ByteBuffer外,其他每一种Buffer都具有完全一样的操作,除了操作类型不一样以外。ByteBuffer可以用于绝大多数标准I/O操作的接口。
在NIO中和Buffer配合使用的还有Channel。Channel是一个双向通道,既可以读也可以写。有点类似Stream,但是Stream是单向的。应用程序不能直接对Channel进行读写操作,而必须通过Buffer来进行。
下面以一个文件复制为例,简单介绍NIO的Buffer和Channel的用法,代码如下:
1 | public class NioCopyFileTest { |
代码中注释写的很详细了,输入流和输出流都对应一个Channel通道,将数据通过读文件channel读取到缓冲中,
然后再通过写文件channel写入到缓冲中。这样就完成了文件复制。注意:缓冲在文件传输中起到的作用十分大,
可以缓解内存和硬盘之间的性能差异,提升系统性能。
3. Buffer详解
Buffer是NIO中最核心的对象,它的一系列的操作和使用也需要重点掌握,这里简单概括一下,也可以参考相关API查看。下面将对Buffer进行详解,包括常用API、使用实例等。
3.1. Buffer API
Buffer中常用的接口有put(), clear(), flip(), rewind()等,这些实际上都是在对Buffer四个基本属性的操作,下面我们来看详细的代码。
- clear: 清空缓冲区
1 | public final Buffer clear() { |
- flip: 读写交换
1 | public final Buffer flip() { |
3.2. Buffer的创建
Buffer的常见有两种方式,使用静态方法allocate()从堆中分配缓冲区,或者从一个既有数组中创建缓冲区。
1 | ByteBuffer buffer = ByteBuffer.allocate(1024);//从堆中分配 |
3.3. 重置或清空缓冲区:
Buffer还提供了一些用于重置和清空缓冲区的方法:rewind(),clear(),flip()。它们的作用如下:
3.4. 读写缓冲区:
对Buffer对象进行读写操作是Buffer最重要的操作,buffer提供了许多读写操作的缓冲区。具体参考API。
3.5. 标记mark缓冲区
标记(mark)缓冲区是一个在数据处理时很有用的功能,它就像书签一样,可以在数据处理中随时记录当前位置,然后再任意时刻回到这个位置,从而简化或加快数据处理的流程。相关函数为:mark()和reset()。mark()用于记录当前位置,reset()用于恢复到mark标记的位置。
代码如下:
1 | ByteBuffer buffer = ByteBuffer.allocate(15);//设置缓冲区大小为15 |
输出结果:
1 | 01234 mark at 456789 |
3.6. 复制缓冲区
复制缓冲区是以原缓冲区为基础,生成一个完全一样的缓冲区。方法为:duplicate()。这个函数对于处理复杂的Buffer数据很有好处。因为新生成的缓冲区和元缓冲区共享相同的内存数据。并且,任意一方的改动都是互相可见的,但是两者又各自维护者自己的position、limit和capacity。这大大增加了程序的灵活性,为多方同时处理数据提供了可能。
1 | ByteBuffer buffer = ByteBuffer.allocate(15);//设置缓冲区大小为15 |
输出如下:
1 | after buffer duplicate |
3.7. 缓冲区分片
缓冲区分片使用slice()方法,它将现有的缓冲区创建新的子缓冲区,子缓冲区和父缓冲区共享数据,子缓冲区具有完整的缓冲区模型结构。当处理一个buffer的一个片段时,可以使用一个slice()方法取得一个子缓冲区,然后就像处理普通缓冲区一样处理这个子缓冲区,而无需考虑边界问题,这样有助于系统模块化。
1 | ByteBuffer buffer = ByteBuffer.allocate(15);//设置缓冲区大小为15 |
输出结果:
1 | 0 1 20 30 40 50 6 7 8 9 0 0 0 0 0 |
3.8. 只读缓冲区
可以使用缓冲区对象的asReadOnlyBuffer()方法得到一个与当前缓冲区一致的,并且共享内存数据的只读缓冲区,只读缓冲区对于数据安全非常有用。使用只读缓冲区可以保证数据不被修改,同时,只读缓冲区和原始缓冲区是共享内存块的,因此,对于原始缓冲区的修改,只读缓冲区也是可见的。
代码如下:
1 | ByteBuffer buffer = ByteBuffer.allocate(15);//设置缓冲区大小为15 |
结果:
1 | 0 1 2 3 4 5 6 7 8 9 0 0 0 0 0 |
由此可见,只读缓冲区并不是原始缓冲区在某一时刻的快照,而是和原始缓冲区共享内存数据的。当修改只读缓冲区时,会报ReadOnlyBufferException异常。
3.9. 文件映射到内存:
NIO提供了一种将文件映射到内存的方法进行I/O操作,它可以比常规的基于流的I/O快很多。这个操作主要是由FileChannel.map()方法实现的。
使用文件映射的方式,将文本文件通过FileChannel映射到内存中。然后在内存中读取文件内容。还可以修改Buffer,将实际数据写到对应的硬盘中。
1 | RandomAccessFile raf = new RandomAccessFile("D:\\test.txt", "rw"); |
3.10. 处理结构化数据
NIO还提供了处理结构化数据的方法,称为散射和聚集。散射是将一组数据读入到一组buffer中,聚集是将数据写入到一组buffer中。聚集和散射的基本使用方法和对单个buffer操作的使用方法类似。这一组缓冲区类似于一个大的缓冲区。
散射/聚集IO对处理结构化数据非常有用。例如,对于一个具有固定格式的文件的读写,在已知文件具体结构的情况下,可以构造若干个符合文件结构的buffer,使得各个buffer的大小恰好符合文件各段结构的大小。
例如,将”姓名:张三,年龄:18”,通过聚集写创建该文件,然后再通过散射都来解析。
1 | ByteBuffer nameBuffer = ByteBuffer.wrap("姓名:张三,".getBytes("utf-8")); |
通过和通道的配合使用,可以简化Buffer对于结构化数据处理的难度。
注意,ByteBuffer是将文件一次性读入内存再做处理,而Stream方式则是边读取文件边处理数据,这也是两者性能差异的主要原因。
3.11. 直接内存访问
NIO的Buffer还提供了一个可以直接访问系统物理内存的类–DirectBuffer。普通的ByteBuffer依然在JVM堆上分配空间,其最大内存,受最大堆的限制。而DirecBuffer直接分配在物理内存中,并不占用堆空间。创建DirectBuffer的方法是:ByteBuffer.allocateDirect(capacity)。
在对普通的ByteBuffer的访问,系统总会使用一个”内核缓冲区”进行间接操作。而ByteBuffer所处的位置,就相当于这个”内核缓冲区”。因此,DirecBuffer是一种更加接近底层的操作。
DirectBuffer的访问速度远高于ByteBuffer,但是其创建和销毁所消耗的时间却远大于ByteBuffer。在需要频繁创建和销毁Buffer的场合,显然不适合DirectBuffer的使用,但是如果能将DirectBuffer进行复用,那么在读写频繁的场合下,它完全可以大幅度改善系统性能。
4. Buffer操作实例
下面例子很好的解释了Buffer的工作原理:
1 | ByteBuffer buffer = ByteBuffer.allocate(15);//设置缓冲区大小为15 |
以上代码,先分配了15个字节大小的缓冲区。在初始阶段,position为0,capacity为15,limit为15。注意,position是从0开始的,所以索引为15的位置实际上是不存在的。
接着往缓冲区放入10个元素,position始终指向下一个即将放入的位置,所有position为10,capacity和limit依然为15。
进行flip()操作,会重置position的位置,并且将limit设置到当前position的位置,这时Buffer从写模式进入读模式,这样就可以防止读操作读取到没有进行操作的位置。所有此时,position为0,limit为10,capacity为15。
接着进行五次读操作,读操作会设置position的位置,所以,position为5,limit为10,capacity为15。
在进行一次flip()操作,此时可想而知position为0,limit为5,capacity为15。